Tìm hiểu về Data Analysis

Bài viết này sẽ hướng dẫn các bước cơ bản:
- Tìm data phù hợp rồi collect chúng
- Đọc data trong môi trường dev
- Chuẩn bị phân tích bằng cách cleaning và validation.
1. Reading data
Dùng pandas để đọc các format phổ biến như CSV, Excel, HDF5,…
2. Columns và Rows
####df.shape
in ra (n, m) với n là số row và m là số column
####df.columns
in ra list các column ở định dạng string
Dataframe giống như Dictionary khi variable name là key (tên cột) còn các giá trị trong row là values. Do đó bạn có thể select column dùng df["key"]. Kết quả là 1 Series các value của cột đó. Dtype của nó là float64.
**Lưu ý: NaN là là giá trị đặc biệt chỉ định value không hợp lệ hoặc bị thiếu. **
3. Clean và Validate
Đây là bảng data chứa cân nặng của baby ta dùng trong các ví dụ sắp tới:

- Đầu tiên ta rút trích mỗi cột mà ta muốn phân tích lưu vào 1 biến:
pounds= df["tên cột"]
ounces= df["tên cột"]
- Ta xem có value gì xuất hiện trong cột mà ta muốn phân tích và mỗi value xuất hiện bao nhiêu lần:
pounds.value_counts().sort_index()
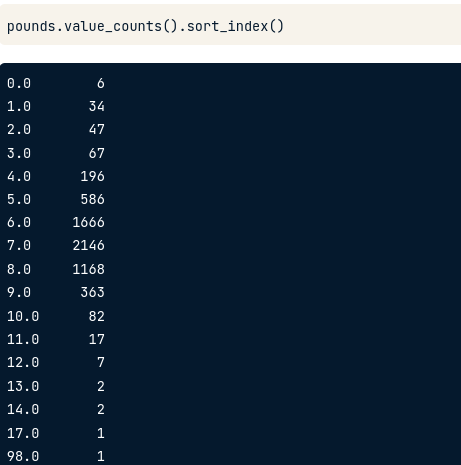
Mặc định kết quả sort theo giá trị nào gặp nhiều nhất. Nên ta thêm sort_index() để nó sort theo giá trị.
=> Sau đó ta quay lại xem bảng data ban đầu để thấy sự hợp lý. Ta có thể kết luận data này đúng và chúng ta đang phân tích đúng.
Series.Describe()
Ta cũng có thể dùng attribute describe để có bảng thống kê mean, phương sai, min và max rồi kết luận như trên.
pounds.describe()
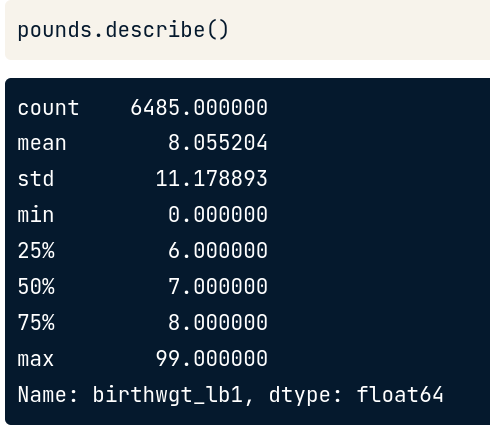
Giải thích bảng trên:
- 50% : giá trị trung vị =7
- mean: trung bình =8, do có chứa các giá trị đặc biệt ít gặp như quá cao hay quá thấp nên không có ý nghĩa lắm. Do vậy, trước khi đưa vào tính toán mean thực sự, ta phải thay thế những giá trị đặc biệt trên bằng NaN (thuộc thư viện numpy) để nó có nghĩa là data này bị mất đi giúp không ảnh hưởng đến số liệu phân tích chung của chúng ta.
Series.Replace()
Tham số đầu tiên là list các giá trị ta muốn replace.
Tham số thứ 2 là giá trị mà ta muốn được replace thành.
Tham số thứ 3 tùy chọn là inplace=True, mặc định không đề cập thì là False. True nghĩa là thay thế series cũ, false là tạo mới series sau khi thay thế.

Trả về kiểu dữ liệu series. Nếu inplace=True thì không cần gán vào biến mới. Ta nhận thấy sau khi thay thế dữ liệu, mean() của series sẽ thay đổi.
Arithmetic với Series
Tùy nhu cầu của bạn muốn tính toán hay combine giá trị của các cột với nhau. Ở ví dụ bài học này, ta sẽ cộng pounds và ounces lại với nhau.
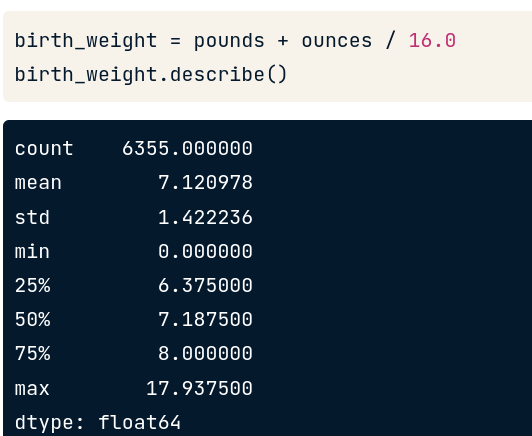
Đầu tiên ta phải đổi giá trị ounces thành pounds bằng cách chia 16 (cách đổi đơn vị cân nặng).
Sau đó ta cộng lại. Kết quả trả về là 1 series là tổng giá trị của 2 series pounds và ounces.
Đến đây ta có thể đưa kết luận giá trị trung bình của 1 đặc tính như cân nặng trong dataset bằng series.describe().
4. Filter và Visualize data
Histogram
Dùng để biểu thị tần suất xuất hiện của giá trị trong dataset. Để dùng biểu đồ này trong python, ta dùng thư viện matplotlib.

-
Tham số thứ 1 là series. Do histogram không nhận giá trị NaN nên chúng ta phải dùng hàm
dropna()để loại bỏ nó trong series. -
Tham số thứ 2 là bin. Số Bin nói với hist là nó muốn chia giá trị trên biểu đồ thành bao nhiêu interval (có thể hiểu là cột theo cân nặng đối với ví dụ) và đếm có bao nhiêu values trong dataset ứng với mỗi bin đó.
Ngoài ra còn các thông số tùy chọn khác xem thêm tại đây: https://matplotlib.org/stable/api/_as_gen/matplotlib.pyplot.hist.html
Quan sát biểu đồ hình trên, ta có thể thấy tần suất baby có cân nặng nhẹ xuất hiện nhiều hơn.
Ta thấy điều này hợp lý vì trong dataset có chứa dữ liệu các em bé sinh non có số tuần mang thai < 37 tuần.
=> Theo đó, ta tiếp tục rút trích dữ liệu của cột chứa số tuần của baby.
Để xem những em bé nào sinh non, ta dùng Boolean Series.
Boolean Series
Trả về series gồm các giá trị True hoặc False cho điều kiện mà ta áp dụng.
Ta gán biểu thức gồm series của cột và điều kiện để trả về series chứa True và False:
preterm = df["tên cột tuần sinh"] <37

Nếu ta tính tổng hay trung bình cho Boolean Series, python sẽ treat True=1 và False=0.
=> Do vậy kết quả của preterm.sum() là 3742. Đây là số lượng baby sinh non ứng với True.
Và khi ta tính trung bình của Series, ta sẽ được tỉ lệ của True. Do đó preterm.mean() cho kết quả ~0.39987. Nghĩ là khoảng 40% số baby có trong dataset này là baby sinh non.
Filter
Ta có thể dùng Boolean Series để filter ra các Series giá trị của cột nào đó mà thỏa điều kiện mong muốn.
Ví dụ để select ra các giá trị cân nặng trong Series birth_weight của các baby sinh non, ta dựa vào Boolean series preterm tương ứng các record True. Python sẽ đối chiếu cùng index với series chứa cân nặng của baby.
Sau đó gán kết quả cho biến lưu series trả về chứa các giá trị cân nặng của em bé sinh non. Từ đó ta dễ dàng tính trung bình cân nặng của đối tượng này.
preterm_weight = birth_weigth[preterm]
Ngược lại, để tính toán trung bình cân nặng ta dùng dấu ~ trước Boolean series để lấy giá trị ngược lại là False.
Kết quả:
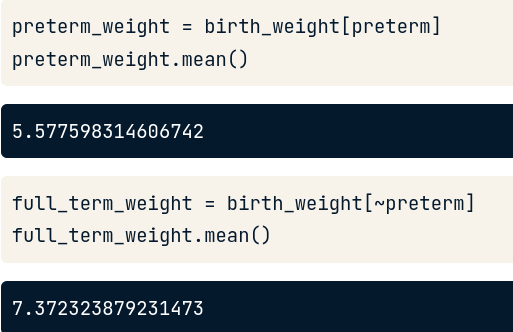
Nhận xét: Trung bình cân nặng của em bé thường sẽ > hơn em bé sinh non, và điều này hiển nhiên hợp lý.
Nâng cao hơn, ta có thể sử dụng kết hợp >2 boolean series để filter. Khi đó ta sẽ cần dùng đến Logical Operators AND hoặc OR.
birth_weight[A & B] # both true
birth_weight[A | B] # either or both true
Resampling
Cuối cùng trước khi có thể trả lời câu hỏi cho set dữ liệu, ta cần thực hiện Resampling.
Nói sơ về Sampling (lấy mẫu) trước. Sampling là quá trình chọn ra một tập con của một quần thể với mục tiêu đánh giá các tính chất của quần thể đó. Cách thức lấy mẫu phụ thuộc trực tiếp vào mục tiêu đánh giá của chúng ta, do đó sampling nằm gần ranh giới giữa việc quan sát khách quan và việc thực hiện các thực nghiệm mang tính chủ quan.
Một số khía cạnh chúng ta cần cân nhắc khi lấy mẫu dữ liệu bao gồm:
- Mục tiêu.Tính chất của quần thể mà chúng ta muốn khảo sát đánh giá.
- Quần thể. Phạm vi khảo sát dựa trên lý thuyết.
- Tiêu chí lựa chọn. Các nguyên tắc cho việc chấp nhận / loại bỏ các quan sát.
- Kích thước mẫu. Số lượng các quan sát được thu nhận trong mẫu.
=> Resampling datacó ý nghĩa là cần khảo sát trên mẫu dữ liệu ta thu được nhiều lần để đánh giá độ chắc chắn cho các ước tính.
Có hai phương pháp resampling thường được sử dụng là bootstrap và k-fold cross-validation:
- Bootstrap. Các mẫu được lấy ra từ dataset một cách ngẫu nhiên, cho phép một mẫu được xuất hiện nhiều hơn một lần.
- k-fold Cross-Validation. Dataset được chia thành k nhóm, mỗi nhóm sẽ được sử dụng để đánh giá 1 lần
5. Probability mass functions (PMF)
PMF Class
Ngoài histogram, ta có thể dùng PMF để quan sát tần số xuất hiện của từng giá trị trong dataset. PMF Class làm việc dựa trên Pandas Series và cung cấp 1 số functions không có trong Pandas.
Tham số đầu tiên có thể là các loại sequence bất kỳ.
pmf_educ = Pmf(educ, normalize=False)
*educ ở đây là Series object
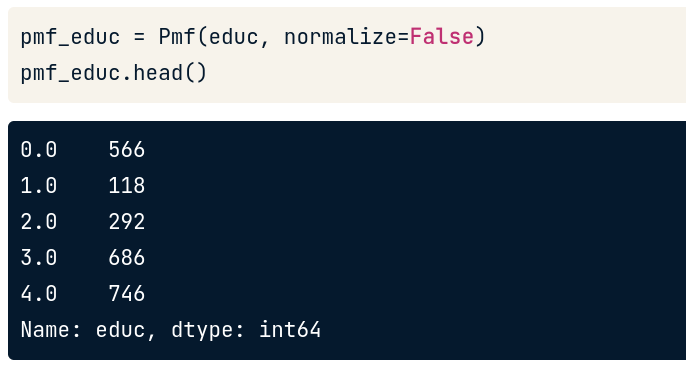
Kết quả trả về 1 PMF object với giá trị ở bên trái và count số lần xuất hiện trong tập dataset ở bên phải.
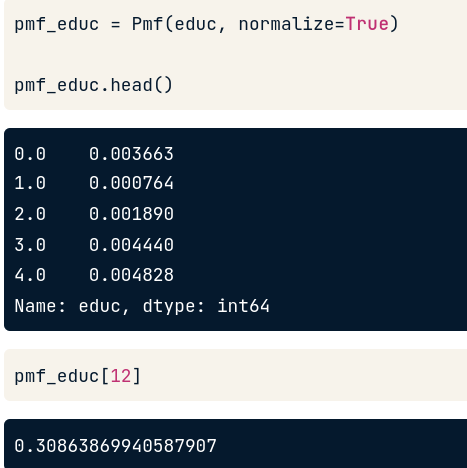
Để lookup tần suất cho giá trị ở bên trái, ta chỉ cần dùng dấu ngoặc vuông:
pmf_educ[12]
Tuy nhiên thông thường khi cần dùng đến PMF thì thường ta muốn biết tỉ lệ xuất hiện của giá trị hơn là đếm
Lúc này ta chỉ cần set tham số thứ 2 là normalize = True. Khi đó cột giá trị bên phải trả về tỉ lệ và tổng cột sẽ =1. Nếu muốn biết % ta chỉ cần *100 là được. Cách lookup cho 1 giá trị bất kỳ cũng tương tự trên.
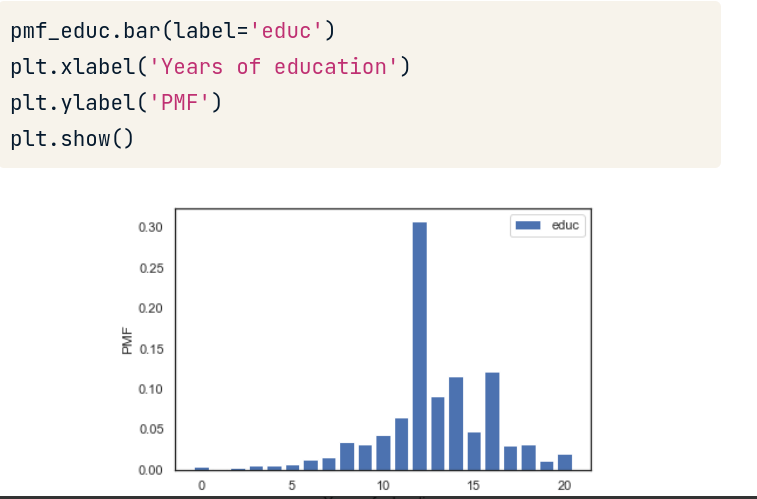
PMF Bar chart
PMF có method riêng để hiển thị biểu đồ tần suất. Tùy ta muốn hiển thị tần suất theo tỉ lệ hay count thì ta dùng method lên biến lưu series ở bước trên.
So sánh Histogram và PMF
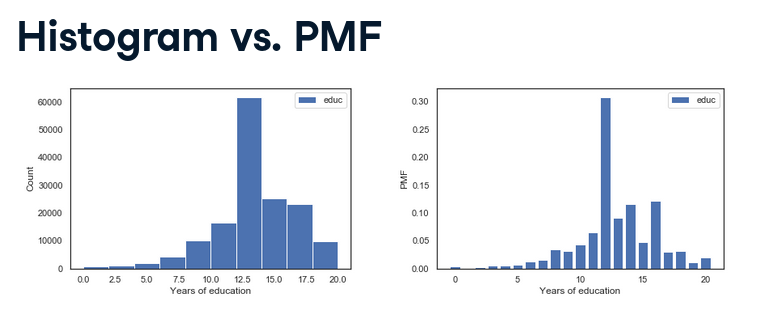
Tùy trường hợp nhưng trong ví dụ hình trên ta nhận xét:
- PMF show tất cả unique value giúp ta thấy rõ chính xác peak của data ở đâu.
- Histogram đặt giá trị theo bin nên làm mập mờ các chi tiết quan trọng, như việc ta không thấy peak nằm ở giá trị 12, 14 và 16.
6. Cumulative distribution functions (CDF)
CDF Class
Ngoài PMF, còn các cách khác để thể hiện distribution đó là CDF.
CDF là cách hay để visualize và so sánh distribution của giá trị.
CDF cách hoạt động gần giống như PMF, khác nhau ở chỗ:
- PMF cho ra tỉ lệ của 1 giá trị trong series từ 0 đến 1.
- CDF cho ra tỉ lệ xuất hiện của các giá trị <= giá trị đang tính toán từ 0 đến 1 (percentile).
cdf_educ = Cdf(educ, normalize=False)
Xem ví dụ sau:

Vẽ biểu đồ plot dùng CDF
Ta chỉ cần dùng class Cdf() và input tham số là sequence của data mà ta muốn biểu thị tần suất. Ở hình dưới là “tuổi”:
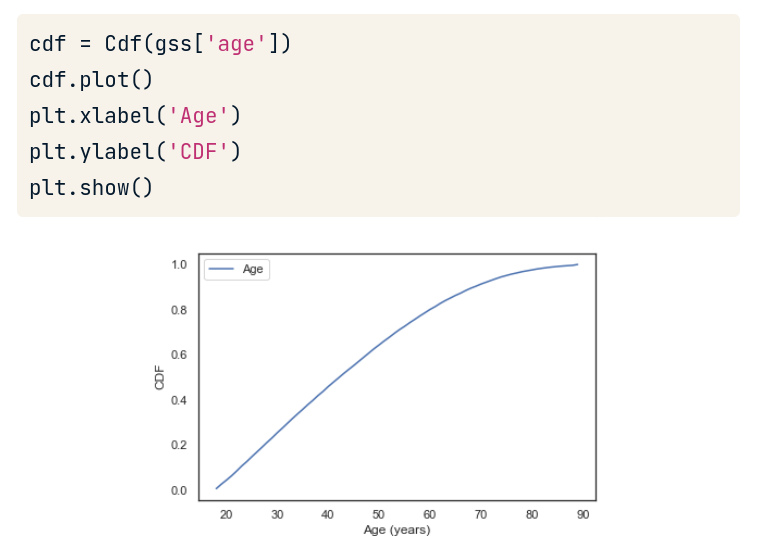
Đặc biệt, cdf có thể được sử dụng như 1 function với input là 1 giá trị cụ thể (biến số nguyên).
q=51
p=cdf(q)
print(p)
Kết quả cho ra 0.66. Nghĩa là có 66% số người có tuổi <=51.
Inverse CDF
CDF là 1 function đảo ngược. Nghĩa là bạn có thể từ giá trị probability (tỉ lệ) mà tra ngược lại giá trị tuổi bằng cách dùng cdf.inverse(giá trị tỉ lệ)
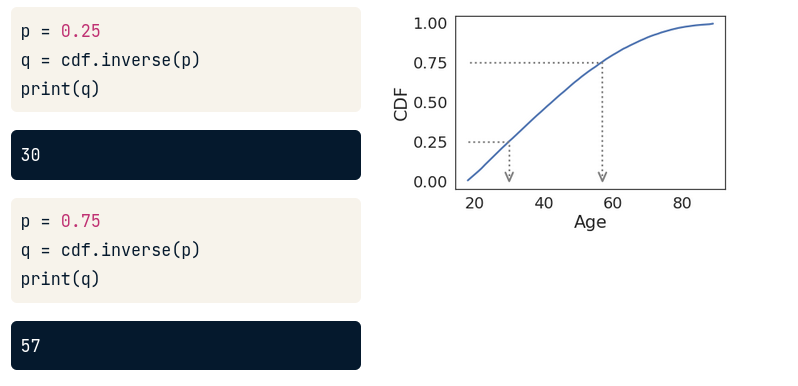
Từ hình trên có thể nói rằng, tuổi 30 là percentile thứ 25 của distribution này. (do p=0,25)
Nói sơ thêm về percentile. Khoảng cách từ 25th đến 75th percentile gọi là interquartile range (IQR), nó giúp đo lường sự trải rộng của distribution. Do vậy IQR tương tự như phương sai (variance) hoặc độ lệch chuẩn (standard deviation). Vì IQR được tính toán dựa trên percentiles nên nó sẽ không bị loại đi những giá trị cực hoặc ngoài rìa (cách mà phương sai làm). Do đó IQR “mạnh mẽ” hơn phương sai, nghĩa là nó vẫn làm tốt công việc của nó dù có giá trị lỗi hoặc giá trị cực trong tập data.
Giá trị cực (extreme value) là gì? Là những giá trị khi xuất hiện sẽ ảnh hưởng lớn đến sự thay đổi về xu hướng hội tụ (độ chụm, độ chính xác) kết quả tính toán chung của tập các số như các phép tính trung bình cộng, trung bình nhân,…
7. So sánh Distributions
Ta có thể dùng PMF hoặc CDF để plot rồi visualize và phân tích. Tuy nhiên với CDF ta sẽ có cái nhìn rõ ràng, không bị nhiễu và biểu đồ đường (line chart) trông sẽ mượt hơn nhiều.
Ta ví dụ tập dataset là income của cư dân trước và sau 1995:
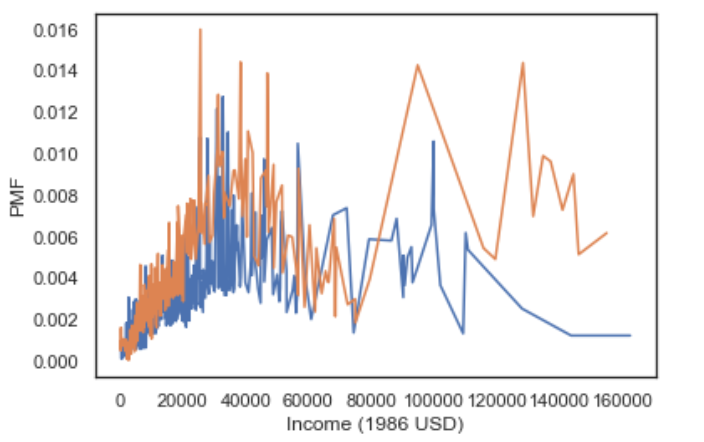
Nếu dùng PMF :

Kết quả chart:
Nếu dùng CDF (khuyến khích)

Kết quả chart:
Nhận xét data:
Dưới 300000$ thì income hầu như không thay đổi trước và sau 1995. Đường màu cam lệch sang phải ở mốc income 100000-150000$ nghĩa là income sau 1995 của những người có thu nhập cao có xu hướng tăng lên.
Changelog
Changelogs take you down the last mile
A changelog can build on your automated version history by giving you an even more detailed record of your work. This is where data analysts record all the changes they make to the data. Here is another way of looking at it. Version histories record what was done in a data change for a project, but don’t tell us why. Changelogs are super useful for helping us understand the reasons changes have been made. Changelogs have no set format and you can even make your entries in a blank document. But if you are using a shared changelog, it is best to agree with other data analysts on the format of all your log entries.
Typically, a changelog records this type of information:
Data, file, formula, query, or any other component that changed
Description of what changed
Date of the change
Person who made the change
Person who approved the change
Version number
Reason for the change
Let’s say you made a change to a formula in a spreadsheet because you observed it in another report and you wanted your data to match and be consistent. If you found out later that the report was actually using the wrong formula, an automated version history would help you undo the change. But if you also recorded the reason for the change in a changelog, you could go back to the creators of the report and let them know about the incorrect formula. If the change happened a while ago, you might not remember who to follow up with. Fortunately, your changelog would have that information ready for you! By following up, you would ensure data integrity outside your project. You would also be showing personal integrity as someone who can be trusted with data. That is the power of a changelog!
Finally, a changelog is important for when lots of changes to a spreadsheet or query have been made. Imagine an analyst made four changes and the change they want to revert to is change #2. Instead of clicking the undo feature three times to undo change #2 (and losing changes #3 and #4), the analyst can undo just change #2 and keep all the other changes. Now, our example was for just 4 changes, but try to think about how important that changelog would be if there were hundreds of changes to keep track of.
Version control system
What also happens IRL (in real life) Image of a woman writing something down. There are two speech bubbles floating near her
A junior analyst probably only needs to know the above with one exception. If an analyst is making changes to an existing SQL query that is shared across the company, the company most likely uses what is called a version control system. An example might be a query that pulls daily revenue to build a dashboard for senior management.
Here is how a version control system affects a change to a query:
A company has official versions of important queries in their version control system.
An analyst makes sure the most up-to-date version of the query is the one they will change. This is called syncing
The analyst makes a change to the query.
The analyst might ask someone to review this change. This is called a code review and can be informally or formally done. An informal review could be as simple as asking a senior analyst to take a look at the change.
After a reviewer approves the change, the analyst submits the updated version of the query to a repository in the company's version control system. This is called a code commit. A best practice is to document exactly what the change was and why it was made in a comments area. Going back to our example of a query that pulls daily revenue, a comment might be: Updated revenue to include revenue coming from the new product, Calypso.
Data cleaning
Data-cleaning verification: A checklist
This reading will give you a checklist of common problems you can refer to when doing your data cleaning verification, no matter what tool you are using. When it comes to data cleaning verification, there is no one-size-fits-all approach or a single checklist that can be universally applied to all projects. Each project has its own organization and data requirements that lead to a unique list of things to run through for verification. Image of a clipboard, pencil and post-it notes
Keep in mind, as you receive more data or a better understanding of the project goal(s), you might want to revisit some or all of these steps. Correct the most common problems
Make sure you identified the most common problems and corrected them, including:
Sources of errors: Did you use the right tools and functions to find the source of the errors in your dataset?
Null data: Did you search for NULLs using conditional formatting and filters?
Misspelled words: Did you locate all misspellings?
Mistyped numbers: Did you double-check that your numeric data has been entered correctly?
Extra spaces and characters: Did you remove any extra spaces or characters using the TRIM function?
Duplicates: Did you remove duplicates in spreadsheets using the Remove Duplicates function or DISTINCT in SQL?
Mismatched data types: Did you check that numeric, date, and string data are typecast correctly?
Messy (inconsistent) strings: Did you make sure that all of your strings are consistent and meaningful?
Messy (inconsistent) date formats: Did you format the dates consistently throughout your dataset?
Misleading variable labels (columns): Did you name your columns meaningfully?
Truncated data: Did you check for truncated or missing data that needs correction?
Business Logic: Did you check that the data makes sense given your knowledge of the business?
Review the goal of your project
Once you have finished these data cleaning tasks, it is a good idea to review the goal of your project and confirm that your data is still aligned with that goal. This is a continuous process that you will do throughout your project– but here are three steps you can keep in mind while thinking about this:
Confirm the business problem
Confirm the goal of the project
Verify that data can solve the problem and is aligned to the goal
After the change is submitted, everyone else in the company will be able to access and use this new query when they sync to the most up-to-date queries stored in the version control system.
If the query has a problem or business needs change, the analyst can undo the change to the query using the version control system. The analyst can look at a chronological list of all changes made to the query and who made each change. Then, after finding their own change, the analyst can revert to the previous version.
The query is back to what it was before the analyst made the change. And everyone at the company sees this reverted, original query, too.
Explore more like this


Làm được gì từ web data?
Mở socket » connect đến đường dẫn và port » Tạo biến string cmd request GET, POST,… » encode string cmd thành dạng byte » gửi request đi.
Comments