Extract - Transform - Load (ETL process)

Tìm hiểu về ETL
I. EXTRACT DATA
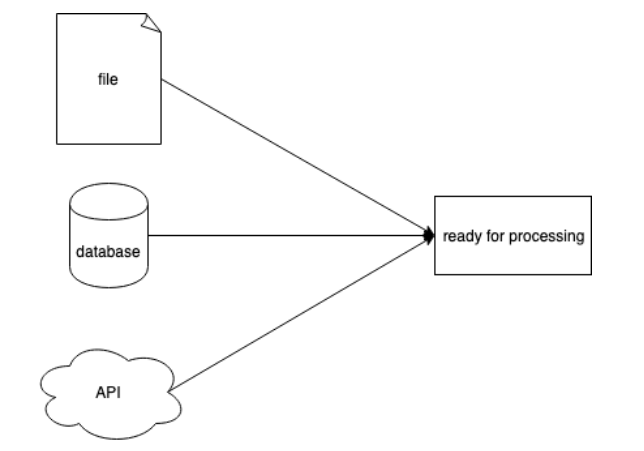
1. Các cách để trích xuất dữ liệu
Có 3 cách:
-
Trích xuất từ file text, như file .txt or .csv Text file có 3 loại là : * Text thuần * Flat file (là file có .tsv hoặc .csv cách nhau bởi dấu “,” hoặc “tab” giữa các giá trị). Những file này có dòng thể hiện các record và cột thể hiện attribute của record. *File JSON: bán cấu trúc, có 4 kiểu dữ liệu atomic là number, string, boolean và null và 2 kiểu dữ liệu dạng composite là array và object. JSON có package hỗ trợ là “json” để import data

-
Trích xuất từ web hoặc APIs của web services, như là Hacker News API

- Thông qua web:
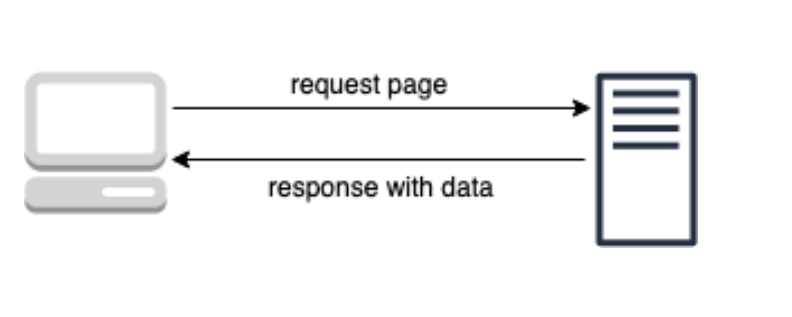
Ví dụ: bạn tìm kiếm thông tin trên google.com thì trình duyệt của bạn sẽ gửi request của bạn đến server của google và google sẽ trả về dữ liệu mà bạn đang tìm kiếm.
* Thông qua API của web:
Không phải lúc nào các trang web cũng trả về kết quả mà người thường có thể đọc ngay, mà các trang web đó sẽ trả về định dạng JSON thông qua API mà chúng ta request.
Ta xem ví dụ request API từ trang Hackernews:
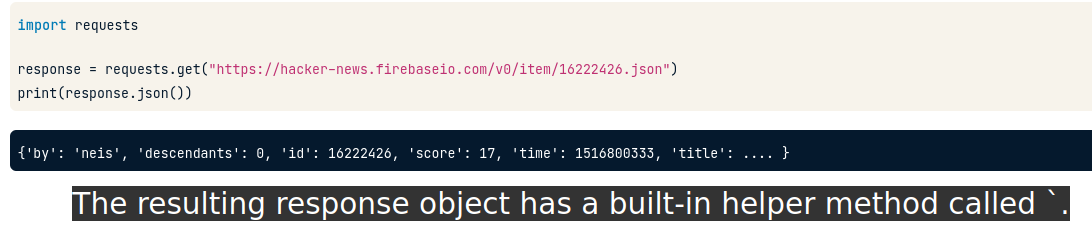 Ta import package “request” rồi dùng method .get() để chèn vào link web cần lấy file JSON.
Sau đó ta dùng method .json() để phân tích file JSON từ kết quả đã lấy được và chuyển hóa nó thành Python object.
Ta import package “request” rồi dùng method .get() để chèn vào link web cần lấy file JSON.
Sau đó ta dùng method .json() để phân tích file JSON từ kết quả đã lấy được và chuyển hóa nó thành Python object.
- Trích xuất từ một database trên web services
Hầu hết các ứng dụng web đều có database để backup và để không bị ảnh hưởng khi tắt server, v.v. Cần phân biệt 2 loại database chính trong trường hợp này:
- Application database : dùng cho trường hợp có nhiều giao dịch được cập nhật, loại này còn có tên gọi là OLTP (online transaction processing)
- Analytical database: được xây dựng cho việc phân tích dữ liệu còn gọi là OLAP (online analytical processing)
2. Trích xuất dữ liệu từ database như thế nào?
- Dùng URI/chuỗi connection, cú pháp như sau:
[database_type]://[user[:password]@][host][:port] - Trong Python, ta dùng connection URI thông qua package
sqlalchemyđể tạo database engine :

Từ engine đã được tạo ra, ta có thể dùng nó để đặt vào 1 số package hỗ trợ nó tương tác với database, đặc biệt là package pandas.
- import requests ```
Lấy dữ liệu từ bài viết của Hackernews về, F12 inspect để lấy URL của nó
resp = requests.get(“https://hacker-news.firebaseio.com/v0/item/16222426.json”)
in dữ liệu vừa parse thành file json ra màn hình
print(resp.json())
parse dữ liệu ra rồi gán value của key “score” vào biến post_score, sau đó in cái biến ra
post_score = resp.json()[“score”] print(post_score)
* Một số ví dụ mở rộng hơn (xem phần 3 để hiểu hơn):
Đọc dữ liệu từ database của postgreSQL, hàm extract dùng SQL query có nhiệm vụ chuyển từ dữ liệu bảng thành kiểu object mà pandas dùng (là dataframe)
Function to extract table to a pandas DataFrame
def extract_table_to_pandas(tablename, db_engine): query = “SELECT * FROM {}”.format(tablename) return pd.read_sql(query, db_engine)
Connect to the database using the connection URI, sử dụng package sqlalchemy
connection_uri = “postgresql://repl:password@localhost:5432/pagila” db_engine = sqlalchemy.create_engine(connection_uri)
Extract the film table into a pandas DataFrame, lưu ý nhớ để tên bảng dạng chuỗi
extract_table_to_pandas(“film”, db_engine)
Extract the customer table into a pandas DataFrame
extract_table_to_pandas(“customer”, db_engine) ```
2. TRANSFORM DATA
1. Một số phương thức chuyển đổi dữ liệu
Có thể thực hiện 1 hoặc nhiều các hình thức trong giai đoạn chuyển đổi dữ liệu đã rút trích:
- Select 1 hay nhiều cột
- Phiên dịch dữ liệu thành code. Ví dụ như New York sẽ biến thành NY
- Kiểm tra dữ liệu có đúng không, nếu dữ liệu không đúng với kiểu dữ liệu hoặc dữ liệu muốn nhận từ cột, ta có thể bỏ record đó đi. Ví dụ như cột ngày nhưng lại chứa giá trị khác ngày.
- Tách dữ liệu của 1 cột thành nhiều cột
- Join dữ liệu từ các nguồn, các bảng khác nhau.
2. Một số ví dụ
Bạn có thể dùng package pandas để chuyển đổi dữ liệu nếu lượng dữ liệu nhỏ. Ta có ví dụ tách dữ liệu từ 1 cột thành 2 cột sử dụng pandas:

Nếu dữ liệu lớn, thông thường người ta sẽ dùng PySpark. Ta có ví dụ chuyển đổi dữ liệu bằng cách join các bảng với nhau. Nhưng trước hết chúng ta cần đẩy dữ liệu lên Spark:
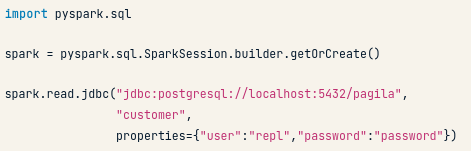
jbdc:để nhắn nhủ với Spark là phải dùng JBDC để kết nối, sau đó, ta input vào tên của bảng và cuối cùng trong properties chúng ta đặt thông tin kết nối vào.
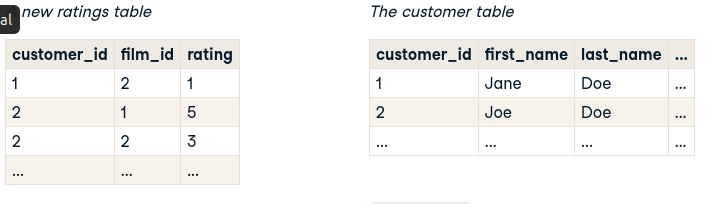
Dưới đây là 2 bảng cần join với nhau thông qua customer_id để tính rating trung bình của mỗi customer dành cho các phim:
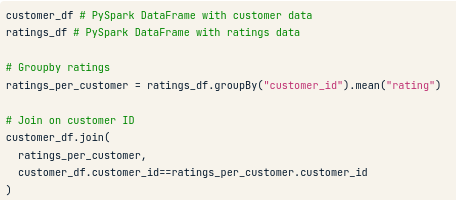
Và làm sao để dùng PySpark join và tính toán dữ liệu? Xem ảnh dưới nhé:
Mình sẽ cho ra thêm các bài viết tìm hiểu sâu hơn về PySpark trong thời gian tới, các bạn hãy cùng chờ đợi nhé!
III. LOAD DATA
Explore more like this
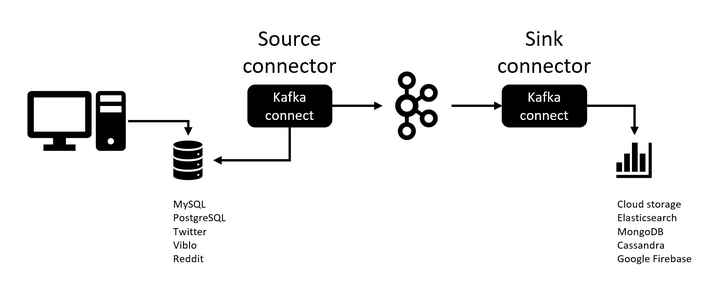


Làm được gì từ web data?
Mở socket » connect đến đường dẫn và port » Tạo biến string cmd request GET, POST,… » encode string cmd thành dạng byte » gửi request đi.
Comments