Import Data - Part 2

1. Import + Load + Tạo HTTP/GET REQUEST
- Lưu file mềm xuống local:
urlretrieve(url, 'filename.csv')
Trước tiên phải from urllib.request import urlretrieve
- Mở và đọc file mềm trên web:
df = pd.read_csv(url, sep=';') -
Show các dòng đầu tiên của df:
print(df.head()) - URL (Uniform/Universal Resource Locator) phần lớn là các địa chỉ web, ngoài ra còn là FTP (file transfer protocol)
URL gồm 2 phần:
- Protocol Identifier : http hoặc https
-
Tên resource: datacamp.com => tạo thành 1 địa chỉ web
-
HTTP (HyperText Transfer Protocol) Là protocol ứng dụng cho các hệ thống thông tin phân tán, cộng tác và siêu phương tiện, nền tảng giao tiếp dữ liệu cho WWW. HTTPS - có độ an toàn bảo mật cao hơn HTTP
- Mỗi khi truy cập vào 1 trang web nghĩa là bạn đang gửi 1 HTTP request cho 1 server. Request này được gọi là GET request, đây là loại request phổ biến nhất.
urlretrieve : gửi GET request và lưu dữ liệu xuống local máy
- HTML (HyperText Markup Language)
2. Các cách gửi GET request:
- Cách 1: sử dụng
urllib.request=>from urllib.request import urlopen, Request
Một số functions của package urllib.request
request = Request(url): đóng gói GET requestresponse = urlopen(request): gửi request và catch phản hồi => trả về HTTP response object có tích hợp method read() và close()html = response.read(): trả về HTML định dạng string-
response.close(): dùng xong nhớ đóng lại - Cách 2: rất phổ biến, sử dụng package
requests
Cho phép gửi HTTP request có tổ chức mà ko cần làm thủ công
requests.get(url) : sau khi import package requests, hàm request.get() sẽ đóng gói request thông qua url, gửi request đi và nhận lại phản hồi và lưu vào biến r.
Ở đây hàm
request.get()sẽ làm nhiệm vụ củaRequest(url)vàurlopen(request đã đóng gói)của cách 1
r.text : r là biến lưu response của hàm trên, sử dụng method .text cho response để chuyển HTML của url sang dạng string.
3. Scraping web trong Python
HTML là sự kết hợp của data có cấu trúc và không cấu trúc.
- Hàm
BeautifulSoup()có tác dụng parse và trích xuất data từ HTML, và làm cho các tag được biểu diễn đẹp hơn.
Cách sử dụng:
from bs4 import BeautifulSoup
Sau khi gửi nhận phản hồi của GET request, ta được file html như trên.
Sau đó, ta dùng hàm BeautifulSoup để extract các data có cấu trúc của file html, lưu kết quả là một object vào một biến mới. Kết quả của hàm BeautifulSoupcó tích hợp hàm .prettify() để làm đẹp kết quả.
soup = BeautifulSoup(html_doc)
print(soup.prettify())
-
Các hàm khác có thể dùng sau khi parse và nhận kết quả từ BeautifulSoup:
soup.title(): trích title của file htmlsoup.get_text(): trích tất cả text của file htmlsoup.find_all(): tìm tất cả các data theo điều kiện hoặc tag nào đó. Ví dụ:for link in soup.find_all('a'): print(link.get('href')hoặc
for link in a_tags: print(link.get('href'))
=> Ở đây, ta sử dụng vòng lặp for kết hợp hàm .find_all() extract data nằm trong tag <a> của file html và in ra từng link của mỗi dòng tìm được, ta cũng có thể lưu soup.find_all() vào một biến nào đó.
Hàm link.get('href') dùng để extract giá trị link của attribute href trong tag <a>
4. Load và khám phá file JSON
FIle JSON nằm ở local
- Bước 1: Tạo connection với file JSON trong local và load file
with open("tên file.json") as json_file : json_data = json.load(json_file)Ở đây json_data là 1 object dictionary, ta check bằng
type(json_data)ra kết quảdict - Bước 2: Sử dụng vòng lặp
forđể in cặp key-value rafor k in json_data.keys(): print(k + ': ', json_data[k])Từ object dictionary trên, ta dùng àm
.keysđể truy cập vào keys của file và dùng cú phápdictionary[key]để truy cập vào value.
5. APIs và tương tác cơ bản
API là gì?
- Là một bộ protocols và routines để xây dựng và tương tác với phần mềm
- Một tập hợp code cho phép 02 chương trình phần mềm giao tiếp với nhau Ví dụ nếu muốn stream data của Twitter thì ta cùng API của Twitter.
- Thông thường data thường được lấy về từ APIs ở định dạng JSON.
URL có gì và làm thể nào để nó biết pull data từ API về?
url = 'http://www.omdbapi.com/?t=hackers'
- http - dấu hiệu là ta đang tạo 1 HTTP request
- www.omdbapi.com - nghĩa là ta đang query OMDB API
?t=hackers- Đây gọi là Query String
- Không có quy ước và không buộc có trong đường dẫn
- Sau dấu
?là phần query. Theo document trên trang chủ OMDB API thì có nghĩ là ta đang muốn trả về data của bộ phim có title (t) ‘Hackers’. Cụ thể xem phần Usage + Parameters.
# Import package
import requests
# Assign URL to variable: url
url = 'https://en.wikipedia.org/w/api.php?action=query&prop=extracts&format=json&exintro=&titles=pizza'
# Package the request, send the request and catch the response: r
r = requests.get(url)
# Decode the JSON data into a dictionary: json_data
json_data = r.json()
print(json_data)
# Print the Wikipedia page extract
pizza_extract = json_data['query']['pages']['24768']['extract']
print(pizza_extract)
Ở 2 dòng code cuối, để biết tại sao code như thế, ta truy cập url trên browser, nó sẽ hiện ra các tab. Ta muốn extract data từ api của url thì ta mở từ tab query > pages > 24768 > extract thì sẽ nhận được data từ api đó.
Load và khám phá Twitter data
# Import package
import json
# String of path to file: tweets_data_path
tweets_data_path = 'tweets.txt'
# Initialize empty list to store tweets: tweets_data
tweets_data = []
# Open connection to file
tweets_file = open(tweets_data_path, "r")
# Read in tweets and store in list: tweets_data
for line in tweets_file:
tweet = json.loads(line)
tweets_data.append(tweet)
# Close connection to file
tweets_file.close()
# Print the keys of the first tweet dict
print(tweets_data[0].keys())
- Đầu tiên ta gán đường dẫn tên file chứa Twitter data ở local máy vào 1 biến.
- Tiếp theo ta tạo 1 mảng rỗng để chứa mỗi dòng tweet là 1 phần tử trong mảng.
- Sau đó ta mở connection đến file local đó thông qua dường dẫn
tweets_data_pathvà lưu vàotweets_file. - Tiếp theo ta dùng vòng lặp for để đọc từng dòng của
tweets_file:- Dùng hàm
json.load(line)để load từng dòng lưu vào biếntweet, để dùng hàm trên phải importjsonpackageNote: mỗi lần load
lineđể lưu vàotweetlà một dictionary. - Sử dụng biến mảng
tweets_datakết hợp hàmappend(tweet)để add thêm phần tử dictionary mới (hay còn gọi là tweet) vào mảng. - In ra tất cả các
keyscủa phần tử đầu tiên (tweet hay dict) của mảng.
- Dùng hàm
Đưa mảng vào Dataframe sử dụng package pandas để phân tích
# Import package
import pandas as pd
# Build DataFrame of tweet texts and languages
df = pd.DataFrame(tweets_data, columns=['text','lang'])
# Print head of DataFrame
print(df.head())
- Hàm
pd.Dataframe()cần 2 tham số là data và column để xây dựng df- Tham số đầu có thể là mảng, dict hoặc dataframe
- Tham số thứ 2 là column label, nếu không có label thì dùng RangeIndex(0,1,2,…n). Nếu có label trong data như ví dụ trên, ta chỉ cần
columns=['text','lang']để chọn label cho column muốn rút giá trị. Ở ví dụ trên ta sẽ tạo 2 cộttextvàlang.
Streaming
# Initialize Stream listener
l = MyStreamListener()
# Create your Stream object with authentication
stream = tweepy.Stream(auth, l)
# Filter Twitter Streams to capture data by the keywords:
stream.filter(track=['clinton', 'trump', 'sanders', 'cruz'])
-
Class
MyStreamListener()được khai báo sẵn tại đây: https://gist.github.com/hugobowne/18f1c0c0709ed1a52dc5bcd462ac69f4 -
Ta tạo object
streambằng cách đưa vào hàmtweepy.Stream()athentication handlerauthvà objectl- stream listener trên. -
Object
streamcó tích hợp hàm.filter(), trong hàm này có attributetrack=[]là list chứa các keyword mà ban muốn filter.
Phân tích data cơ bản
import re
def word_in_text(word, text):
word = word.lower()
text = text.lower()
match = re.search(word, text)
if match:
return True
return False
- Ở trên ta có hàm
word_in_text()để đếm số lượng tweet chứa keyword. Nhưng ở đây chúng ta chưa đếm, mà chỉ đưa kết quả nếu True sẽ +1 vào biến đếm ở bước tiếp theo.
# Initialize list to store tweet counts
[clinton, trump, sanders, cruz] = [0, 0, 0, 0]
# Iterate through df, counting the number of tweets in which
# each candidate is mentioned
for index, row in df.iterrows():
clinton += word_in_text('clinton', row['text'])
trump += word_in_text('trump', row['text'])
sanders += word_in_text('sanders', row['text'])
cruz += word_in_text('cruz', row['text'])
- Tiếp theo ta sẽ tạo list trong Python, mỗi item sẽ có giá trị đếm bắt đầu =0. Mục đích ở đây là để đếm số tweet count được cho mỗi keyword.
- Sử dụng vòng lặp để đi từng row và check, nếu gặp keyword sẽ +1 vào biến đếm. Nếu True (nghĩa là có keyword đó) thì += 1.
Basic Data visualization
# Import packages
import seaborn as sns
import matplotlib.pyplot as plt
# Set seaborn style
sns.set(color_codes=True)
# Create a list of labels:cd
cd = ['clinton', 'trump', 'sanders', 'cruz']
# Plot the bar chart
ax = sns.barplot(cd, [clinton, trump, sanders, cruz])
ax.set(ylabel="count")
plt.show()
- Đầu tiên cần import 2 package như trên để vẽ biểu đồ
- Hàm
sns.barplot()có 2 tham số:- Tham số đầu: list label cần biểu diễn giá trị
- Tham số thứ 2: list chứa giá trị của các label cần biểu diễn. List này đã được khởi tạo và đếm ở code trước đó.
Explore more like this
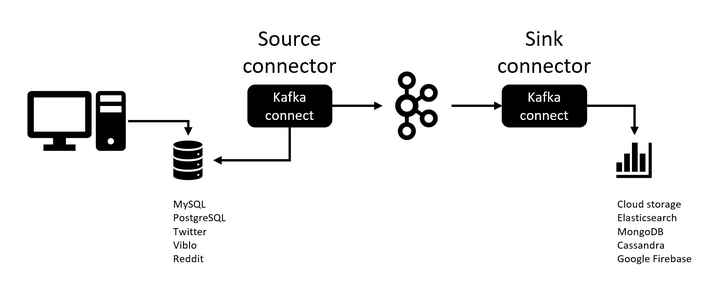


Làm được gì từ web data?
Mở socket » connect đến đường dẫn và port » Tạo biến string cmd request GET, POST,… » encode string cmd thành dạng byte » gửi request đi.
Comments