Kafka Connect

Write-head logging
WAL là một trong các kỹ thuật cung cấp tính chất Atomicity và Durability (2 trong số 2 tính chất ACID) trong hệ thống database.
Các thay đổi được lưu lại trong log và sẽ phải được ghi vào trong stable storage (thường không phải là disk vì không có tính chất automic) trước khi các thay đổi đó được ghi vào database.
Trong 1 cái hệ thống sử dụng WAL, tất cả mọi thay đổi được ghi vào log trước khi được áp dụng. Thường thì các thay đổi redo và undo được lưu vào trong log.
Ok, mục đích sử dụng của WAL có thể hiểu được qua ví dụ sau:
-
Khi mà chương trình của bạn đang chạy nhưng bị crash hay mất điện giữa chừng. Sau khi khởi động lại thì chương trình cần biết là operation đã thành công hay thành công 1 nửa hay thất bại hay như thế nào.
-
Lúc này nếu sử dụng WAL, thì chương trình có thể xem log để so sánh với những gì đã thực hiện và chưa thực hiện lúc chương trình bị crash và quyết định xem sẽ undo lại operation hay hoàn tất nốt operation hoặc giữ nguyên mọi thứ.
Các hệ quản trị cơ sở dữ liệu khác nhau sẽ có tên gọi cho WAL log khác nhau. Trong MySQL sẽ là binlog.
Ngoài ra 1 transaction được xem là thành công thì các statements của nó phải toàn bộ thành công, ngược lại nếu 1 trong các statement cấu thành 1 transaction thất bại thì là thất bại. Điều này đảm bảo tính automicity trong ACID để được gọi là 1 database transaction.
Kafka Connect
Kafka Connect là 1 component của Kafka giúp kết nối và transfer data giữa các external system với Kafka.
Bây giờ đi từ use case, bạn cần kết nối data giữa Order database đến Kafka Cluster và từ Kafka Cluster kết nối đến Data warehouse để phân tích data, có 2 cách:
- Cách 1: Sửa source code của Order service để tạo producer trong đó đọc data từ database rồi gửi đến Kafka cluster.
Nhược điểm: khi cần thay đổi code cho producer thì phải deploy lại service có thể gây downtime ảnh hưởng đến người dùng. Phụ thuộc vào Order service chạy hay không chạy (nếu service có multi-replicas thì không sao).
- Cách 2: Tạo Kafka producer độc lập đọc data từ Order database và produce đến Kafka broker.
Nhược điểm: cần maintain thêm service này cho Kafka producer. Cần thiết kế để scalable, fault tolerance,…
=> Kafka Connect sử dụng cách 2. Hiện Kafka connect đã có open-source framework cho phép chọn loại connector (là loại source/target) rồi config và sử dụng, hoặc bạn có thể tự viết connector riêng dựa trên framework này.
Ta sử dụng có sẵn thì sẽ không cần 1 dòng code nào mà chỉ cần tạo config để nó hoạt động còn lại Kafka connect sẽ tự lo.
Tương tự ta sẽ cần config cho 1 Kafka connect để connect từ Kafka cluster đến Data warehouse.
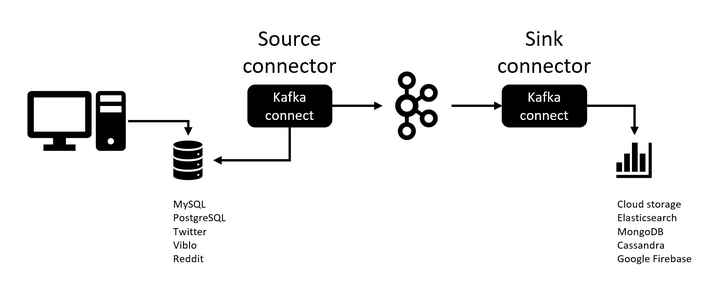
Có 2 loại connect là Source connector và Sink connector:
Bên trái được gọi là
Source connector: pull data từ source system và gửi đến Kafka cluster. Bên phải làSink connector: consume data từ topic và sink đến hệ thống đích.
Cách hoạt động của Kafka connect
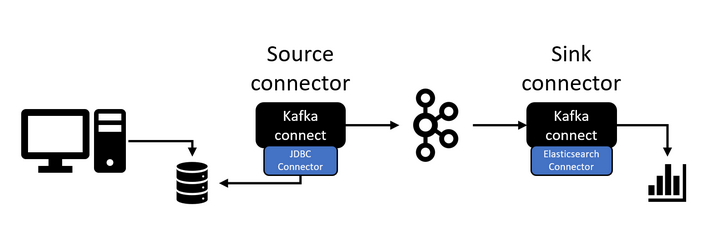
Kafka connect như 1 interface, ở abstract level, tạo các API để 3rd party có thể sử dụng dựa trên cách hoạt động của từng service.
Nó chỉ cung cấp phần API đóng mở connection, tạo statement, execute query, tương tác với database. Còn lại là việc của database driver cụ thể như JDBC driver cho Mysql,…
Kafka connect framework bao gồm:
Source connector:
SourceConnector.
SourceTask.
Sink connector:
SinkConnector.
SinkTask.
=> Ta chỉ cần implement 2 class cho mỗi Kafka connect là:
SourceConnector và SourceTask.
Hoặc SinkConnector và SinkTask.
Còn lại 1 số thứ cơ bản như độ scalibility , fault tolerance hay error handling đã có Kafka connect lo.
Kafka connect Transformation
Đôi khi trong quá trình transfer data, ta có thể cần phải điều chỉnh messages để biến đổi nó theo như format mà chúng ta muốn.
Khi đó ta có thể dùng tính năng Single Message Transformations - SMTs để làm điều này trong config của Source connector hoặc Sink connector.
SMTs bao gồm 1 số thao tác phổ biến:
- Thêm field mới cho message.
- Filter message dựa trên field.
- Rename field.
- Route message đến các topic khác nhau.
Kafka connect Architecture
Gồm các keyword chính:
- 1) Worker : là công nhân thực thi các task để gửi msgs đến Kafka cluster. (còn việc read/write từ/đến source thì là của Source/SinkTask theo config của ta xong rồi mới chuyển cho worker thực thi nhé)
Worker có 2 khả năng đặc biệt:
* Fault tolerance: khi worker gặp sự cố sẽ phân task cho worker khác handle tiếp.
* Self-managed: khi có worker mới các task sẽ được phân phối lại đảm bảo load balance.
=> Có 4 tính năng Reliability, High avalability, Scalability, Load balancing.
- 2) Connector : tạo API kết nối với các system
- 3) Task : ví dụ transfer từ table 1 sang table 2 là 1 task
OK, vậy việc của chúng ta bây giờ là:
Làm thế nào để phân chia input thành các phần có thể thực hiện đồng thời. Làm thế nào để tương tác với các external system.
Debezium
Mysql có binlog dùng cho việc replication và recovery. File này chứa các thay đổi của database (trước khi ghi vào database) bao gồm cả thay đổi về dữ liệu table và cả schema của table.
Sau đó các thay đổi này mới được ghi vào database rồi sẽ được commit.
Debezium Mysql connector là một plugin trong Kafka giúp kết nối Mysql với Kafka.
Connector này sẽ đọc sự thay đổi trong binlog và tạo ra các event INSERT/UPDATE/DELETE để đẩy lên Kafka.
Mysql được cài đặt sẽ xóa data trong binlog sau 1 thời gian ngắn nên Debezium Mysql connector sẽ chụp nhanh snapshot của hiện trạng dữ liệu và đọc nó ngay tại thời điểm được chụp.
Cách hoạt động của Debezium
- Schema history topic: Binlog sẽ vừa lưu thay đổi về row-level data vừa lưu DDL statement để biết được schema tại 1 thời điểm có thay đổi không và thay đổi ra sao để produce event lên kafka chính xác.
Còn trên database của kafka topic, connector sẽ vừa lưu DDL statements vừa lưu vị trí có DDL statement trong binlog.
Khi có sự cố crash phải restart lại connector, nó sẽ đọc trong binlog tại 1 thời điểm cụ thể x. Connector sẽ rebuild lại schema từ database history topic Kafka cho đến thời điểm x mà nó được start lại trong binlog.
- Schema change topic: Bạn có thể cấu hình để Debezium Mysql connector produce các “schema change event” mô tả sự thay đổi của database.
Message được connector gửi đến cho Kafka topic name
Message này chứa payload và có thể tùy chọn để chứa luôn schema của change event message. Phần payload gồm:
ddl
Provides the SQL CREATE, ALTER, or DROP statement that results in the schema change.
databaseName
The name of the database to which the DDL statements are applied. The value of databaseName serves as the message key.
pos
The position in the binlog where the statements appear.
tableChanges
A structured representation of the entire table schema after the schema change. The tableChanges field contains an array that includes entries for each column of the table. Because the structured representation presents data in JSON or Avro format, consumers can easily read messages without first processing them through a DDL parser.
Thực hành
-
Debezium: https://debezium.io/documentation/reference/1.8/tutorial.html#viewing-create-event
-
Streaming from Mysql to Postgres và Elasticsearch https://debezium.io/blog/2018/01/17/streaming-to-elasticsearch/
Ref: https://debezium.io/documentation/reference/1.8/connectors/mysql.html https://docs.confluent.io/kafka-connect-elasticsearch/current/configuration_options.html https://docs.confluent.io/kafka-connect-elasticsearch/current/overview.html https://baonq5.notion.site/Sample-connector-config-55b33df3898346fc93c94c7a697d44a6
https://en.wikipedia.org/wiki/Write-ahead_logging https://viblo.asia/p/010-apache-kafka-connect-concept-gAm5ymNL5db https://en.wikipedia.org/wiki/ACID
Explore more like this


Làm được gì từ web data?
Mở socket » connect đến đường dẫn và port » Tạo biến string cmd request GET, POST,… » encode string cmd thành dạng byte » gửi request đi.
Comments